贝叶斯公式描写叙述的是一组条件概率之间相互转化的关系。
在机器学习中。贝叶斯公式能够应用在分类问题上。
这篇文章是基于自己的学习所整理。并利用一个垃圾邮件分类的样例来加深对于理论的理解。
这里我们来解释一下朴素这个词的含义:
1)各个特征是相互独立的,各个特征出现与其出现的顺序无关;
2)各个特征地位同等重要;
以上都是比較强的如果
以下是朴素贝叶斯分类的流程:

这样我们就分别求出了这些特征各个类别下的条件概率,非常直观的,对于各个特征的联合概率分布就是各个条件概率进行相乘。如上式。可是这样会出现下面几个问题:
1)若某一个词未出如今字典中,那么其条件概率就会为0。那么总体的联合概率也就为0。为了避免这样的情况的
出现,这里会引入 Laplace smoothing的操作:假定输入样本中各个特征出现的次数至少为1,这样在求一个特征出
现的概率时对于分母。要加上其总的类别m;能够表述为例如以下公式,
p(w|h)=(实际出现的次数+1)/(总的特征出现次数+m)
2)还有一个问题是,若一个样本中特征个数非常多,那 么可能会出现这种情况,单个特征出现的概率非常少,那么联合
概率相乘时。终于的值会很小。在计算机中可能出现下溢。为了避免这样的情况出现,能够对联合概率取对数
log(a*b)=log(a)+log(b)
上式能够转换为:
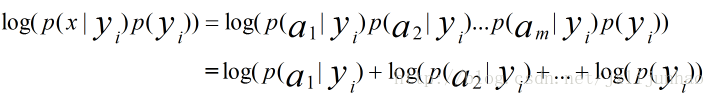
以上都是训练过程中会常常遇到的问题。
经过训练后,就能够得到非常多组这种公式。那么对于一封新的邮件过来了
怎么去判定其是否为垃圾邮件呢?
这里就会涉及到怎么样将 单词这种特征转化成计算机能够方便处理的数字,非常直观的就是建立一个已知垃圾邮件中常常出现的单词的字典(向量)。对于新邮件。就能够将其转换到一个与字典相同大小的向量,出现的单词在对应的索引处标为‘1’,否则标 ‘0’。
下一步就是将得到的这个向量分别与训练得到的对数概率进行相乘了。
以下是python代码,来自机器学习实战这本书。
from numpy import *def loadDataSet(): postingList=[['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'], ['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'], ['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'], ['stop', 'posting', 'stupid', 'worthless', 'garbage'], ['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'], ['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']] classVec = [0,1,0,1,0,1] #1 is abusive, 0 not return postingList,classVec def createVocabList(dataSet): vocabSet = set([]) #create empty set for document in dataSet: vocabSet = vocabSet | set(document) #union of the two sets return list(vocabSet)def setOfWords2Vec(vocabList, inputSet): returnVec = [0]*len(vocabList) for word in inputSet: if word in vocabList: returnVec[vocabList.index(word)] = 1 else: print "the word: %s is not in my Vocabulary!" % word return returnVecdef trainNB0(trainMatrix,trainCategory): numTrainDocs = len(trainMatrix) numWords = len(trainMatrix[0]) pAbusive = sum(trainCategory)/float(numTrainDocs) p0Num = ones(numWords); p1Num = ones(numWords) #change to ones() p0Denom = 2.0; p1Denom = 2.0 #change to 2.0 for i in range(numTrainDocs): if trainCategory[i] == 1: p1Num += trainMatrix[i] p1Denom += sum(trainMatrix[i]) else: p0Num += trainMatrix[i] p0Denom += sum(trainMatrix[i]) p1Vect = log(p1Num/p1Denom) #change to log() p0Vect = log(p0Num/p0Denom) #change to log() return p0Vect,p1Vect,pAbusivedef classifyNB(vec2Classify, p0Vec, p1Vec, pClass1): p1 = sum(vec2Classify * p1Vec) + log(pClass1) #element-wise mult p0 = sum(vec2Classify * p0Vec) + log(1.0 - pClass1) if p1 > p0: return 1 else: return 0
很多其它内容能够參考下面博客: